
지난 포스트에서 학습은 모델 적용, 모델 평가, 모델 업데이트의 반복이라고 간단히 설명하였는데, 기계학습에서 학습이 어떻게 진행되는지 조금 더 심도있게 들여다보자.
학습 프로세스
Andrew Ng 교수님의 Coursera 강의에서는 지도학습의 과정을 아래와 같이 설명하였다.

Training Set(훈련데이터)를 바탕으로 알고리즘을 학습시킨 다음, 완성된 가설(h)를 적용하여 문제 x에 대한 예측값 y를 도출해 내는 것이 기계학습을 사용하여 문제를 해결하는 과정이다. 하지만 위 그림에서는 알고리즘을 어떻게 학습시키는 것인지는 설명하고 있지 않다. 그래서 내가 공부한 내용을 바탕으로 아래와 같이 학습 과정을 도식화하였다.
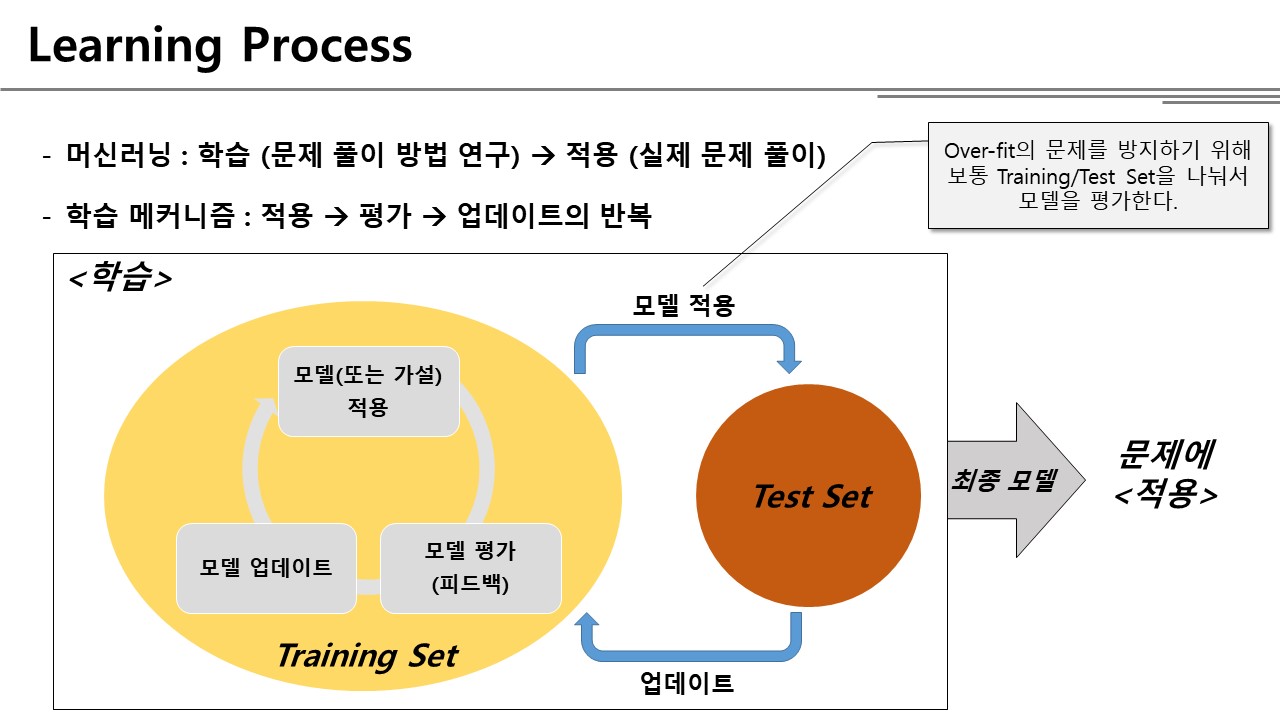
훈련 데이터를 사용하여 학습을 진행할 때 크게 세 단계를 거치는데,
- 모델(또는 가설)을 세워서 적용하고,
- 세운 가설을 평가하고,
- 평가를 바탕으로 가설을 업데이트한다.
위의 3단계를 반복하면서 주어진 문제를 가장 잘 풀 수 있는 가설을 찾아가는 것이 학습의 과정이다.
1단계에서 세우는 모델의 종류에 대해서는 하나씩 차근히 공부하기로 하고, 이번과 다음 포스트에서는 2단계와 3단계가 어떻게 수행되는지 알아보도록 하자.
모델(가설) 평가
※ 아래에서 설명하는 내용은 지도학습(Supervised Learning)을 대상으로 하는 것임을 참고하기 바란다.

현재 내가 세운 가설을 데이터에 적용하였을 때 기대하는 수준의 성능이 나오는지를 확인하고 모델을 수정하는 과정을 반복하는 것이 학습이라고 하였다. 그렇다면 무엇을 기준으로 모델의 성능을 평가할 수 있을까?
지도학습 모델의 경우 항상 정답이 주어진다는 것을 상기한다면, 모델을 적용하여 내가 푼 문제와 실제 정답이 얼마나 다른지(오차)를 측정한 값을 모델 평가의 기준으로 삼을 수 있을 것이다. 이를 계산하는 계산식을 손실함수(Loss Function) 혹은 비용함수(Cost Function)이라고 하고, 문제에 따라 평균 제곱 오차 혹은 교차 엔트로피 오차 두 가지 손실함수 중 하나를 사용할 수 있다.
기계학습의 문제 유형은 크게 예측과 분류로 구분된다는 것을 기억하고 있는가? 문제 유형은 Output Y로도 구분할 수 있는데, Y값이 연속적인 경우(주식 가격, 부동산 가격 등)는 보통 회귀(Regression) 문제로 접근하고, Y값이 이산적인 경우는 분류(Classification) 문제로 접근한다.
평균 제곱 오차 (MSE, Mean Squared Error)
평균 제곱 오차는 회귀 모델을 평가하는 식으로, 예측값 Y’와 실제 정답 Y의 오차를 제곱하여 더한 값을 계산하는데 함수는 다음과 같다.
\(\large {L = \frac { 1 }{ 2m } \sum _{ i=0 }^{ m }{ { (\hat { y } - y) }^{ 2 } } = \frac { 1 }{ 2m } \sum _{ i=1 }^{ m }{ { (h(x) - y) }^{ 2 } }} \)
식에서 y’(y-hat)은 모델을 적용하여 도출된 예측값, y는 훈련 데이터에서 주어진 실제 정답이다. m은 훈련 데이터의 개수로 100개의 데이터가 있다면 각 데이터의 오차를 모두 더하여 평균을 낸 값이 해당 모델의 평균 제곱 오차 값이다. 당연히 예측값과 실제값의 차이가 적은 모델이 성능이 좋은 모델이다.
평균 제곱 오차를 계산하는 함수를 파이썬으로 작성해보면 아래와 같다.
import numpy as np
"""
x : 훈련데이터 m개가 각 행에 저장되어 있는 Input 데이터
t : 각 x 데이터에 대응되는 결과값 (Labeled Data)
Return : 예측 결과와 실제값의 평균제곱오차값
"""
def mean_squeared_error(x, t):
y = predict(x) # 현재의 가설을 바탕으로 x 데이터에 대한 예측값 y를 리턴하는 함수
m = x.shape[0] # 훈련 데이터의 개수
mse = 1 / (2*m) * np.sum((y - t)**2)
return mse
교차 엔트로피 오차 (CEE, Cross Entropy Error)
교차 엔트로피 오차는 주로 분류 모델을 평가하는데 사용하며, 특히 CEE를 사용하기 위해서는 Output Y값이 원-핫 인코딩(One-hot Encoding)으로 구성되어야 한다.
- 원-핫 인코딩 : Input을 N개 그룹으로 나누는 분류 문제가 있을 때, 데이터에 해당하는 그룹은 1, 그 밖의 나머지 그룹은 0으로 표현하는 방법. 예를 들어 손글씨 인식 문제의 경우 글씨를 0부터 9 중 하나의 숫자로 분류하게 되는데, 주어진 이미지가 3인 경우, [0 0 0 1 0 0 …]과 같이 나타낸다.
하나의 샘플에 대해 교차 엔트로피 오차는 아래와 같은 식으로 구한다.
\(\large {L=-\sum _{ i=1 }^{ C }{ y\ln { \hat { y } } } }\)
식에서 C는 분류 그룹의 개수, 손글씨 인식 문제는 C=10이다. y과 y’는 모두 원-핫 인코딩으로 표현되었고, 곱은 행렬곱이 아닌 원소곱(element-wise)이다. 즉, 이 식은 예측값 중에서 실제 정답 그룹의 로그값만 취한다.
\(\large {\left[ \begin{matrix} 0 & 1 & 0 \end{matrix} \right] *\left[ \begin{matrix} lnA & lnB & lnC \end{matrix} \right] =\left[ \begin{matrix} 0 & lnB & 0 \end{matrix} \right] }\)
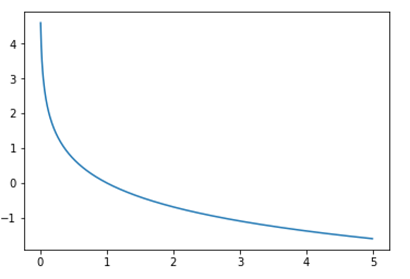
위 그래프에서 확인할 수 있듯이 \(\ln { 1 } =0\) 이기 때문에 정답 레이블과 예측 레이블이 같다면 오차는 0이 되고, 자연로그의 음수값을 취했기 때문에 예측 레이블이 0에 가까워질수록 오차는 커진다. m개의 훈련 데이터에서 교차 엔트로피 오차를 구하려면 각 샘플의 오차들을 모두 합하면 된다. 당연히 합의 작을수록 실제값과 예측값의 차이가 적다는 것이기 때문에 모델의 성능이 좋다는 것을 의미한다.
\(\large {L=-\sum _{ j=1 }^{ m }{ \sum _{ i=1 }^{ C }{ y\ln { \hat { y } } } } }\)
교차 엔트로피 오차를 계산하는 함수를 파이썬으로 작성해보면 아래와 같다.
import numpy as np
"""
x : 훈련데이터 m개가 각 행에 저장되어 있는 Input 데이터
t : 각 x 데이터에 대응되는 결과값 (One-hot encoded)
Return : 예측 결과와 실제값의 교차 엔트로피 오차값
"""
def mean_squeared_error(x, t):
y = predict(x) # 현재의 가설을 바탕으로 x 데이터에 대한 예측값 y를 원-핫 인코딩으로 리턴하는 함수
delta = 1e-7
cee = -np.sum(t * np.log(y+delta)) # y = 0일 때 로그가 무한대로 발산하기 때문에 delta 값을 더해서 방지
return cee