
최근 AI, 인공지능 분야가 IT 업계를 포함한 전 분야에서 활발히 논의되기 시작하면서, 해당 분야를 공부해보고자 하는 사람들이 늘고 있다. 나 또한 그 중 하나로, 데이터 분석을 포함해서 인공지능, 머신러닝, 딥러닝, 강화학습 등 여러 분야에 대해서 (얕고 넓게) 공부해보고 있다. 인공지능 분야가 흥미로운 것은 컴퓨터 공학을 전공하는 사람이 아니더라도 간단한 파이썬 프로그래밍 지식만 있으면 누구나 (쉽지는 않지만) 공부하고 실습해 볼 수 있다는 것이다. 또한, 인공지능 기술이 적용되는 분야는 IT분야 뿐만 아니라 의학, 사회학, 언어학 등 데이터를 분석하여 의미있는 결과를 도출하고자 하는 분야는 어디든 적용할 수 있기 때문에 전공/비전공의 의미가 무색해졌다.
내가 잘 하는 것 중 하나가 새로운 것을 빠르게 배워서 남들에게 쉽게 설명하는 것이다. 그래서 이번에는 모두들 공부해보고 싶어하지만 섣불리 엄두내기 힘들어하는 인공지능(이라고 하기에는 거창하지만)의 기초 머신러닝 분야를 차근차근 설명해나가고자 한다. 본인도 아직 초보자이기 때문에 내가 공부했던 내용들을, 내가 이해했던 방식대로 쉽게 풀어서 설명하도록 노력할 것이다.
이번 첫번째 연재에서는 머신러닝이란 것이 무엇인지, 학습을 시킨다는 것은 어떤 의미인지 등 기본적인 정의부터 잡아보려고 한다.
Machine Learning (기계학습)이란 무엇인가
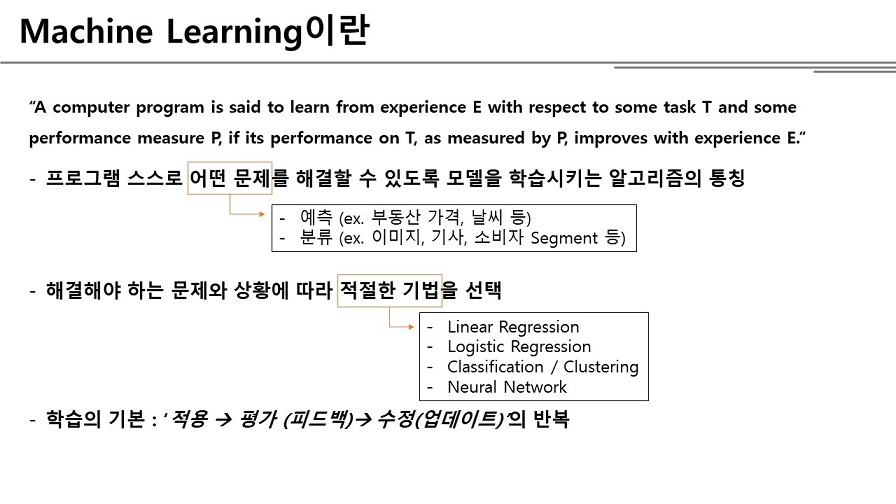
“A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.” (Tom M. Mitchell)
컴퓨터 프로그램은 본디 특정한 기능을 수행하기 위한 목적으로 만들어진다. 프로그래밍이라는 것은 쉽게 말해 컴퓨터에게 이런 상황에서는 이렇게 동작하라, 저런 상황에서는 저렇게 동작하라는 지시를 개발자가 일일이 알려주는 것이라고 이해할 수 있는데, 이런 컴퓨터가 사람처럼 학습을 한다니 이게 무슨 의미일까?
머신러닝은 프로그램 스스로 어떤 문제를 해결할 수 있도록 모델을 개선해가는 알고리즘을 뜻한다
기계학습은 문제를 해결하기 위한 것이다. 여기서 문제라는 것은 보통 크게 두가지로 구분하는데, 하나는 예측이고, 다른 하나는 분류이다. 예측 문제의 예로는 주식 가격, 날씨 등이 있고, 분류 문제에는 이미지, 기사, Market Segment 분류 등이 있을 수 있다. 이러한 문제를 사람이 직접 푼다고 생각하면 어떤 식으로 접근할까 생각해보자. 주식 가격을 예측하고자 한다면 일단 과거의 주식 관련 데이터를 모을 것이고, 다양한 데이터들에서 가격에 영향을 미치는 요인들을 추출한 다음, 요인들과 가격 변동 간의 상관관계(패턴)를 찾아내려고 할 것이다.
기계학습이란 위와 같은 문제를 해결하고자 할 때, 결과값에 영향을 미치는 요인들, 요인들과 결과값의 상관관계를 사람의 조작 없이 스스로 모델을 개선해가는 알고리즘을 가리킨다. 주식과 관련된 데이터들을 기계학습 알고리즘에 제공하면 스스로 모델을 수정해가면서 예측 성능이 가장 좋은 모델을 만들어가는 것이다. 해결해야 하는 문제에 따라서 각기 다른 기계학습 알고리즘을 적용해야 하고 그 기법들에 대해서는 하나씩 차근차근히 배워나갈 것이다.
학습은 모델 적용, 모델 평가, 모델 업데이트의 반복 우리가 수학 문제를 푼다고 가정해보자. 문제가 주어지면 일단 내가 알고 있는 방법으로 문제를 풀어보고(모델 적용) 정답(모델 평가)이 맞으면 다행이지만, 혹시나 틀렸다면 문제 푸는 방법을 고친 후(모델 업데이트) 다시 풀어볼 것이다. 마찬가지로 기계학습에서도 문제를 해결하고자 할 때 주어진 문제에 맞는 모델을 설정한 다음, 데이터에 모델을 적용하고, 성능이 얼마나 좋은지 모델을 평가하고, 성능을 개선할 수 있도록 모델 업데이트 하는 3개의 동작을 반복한다.
Supervised vs. Unsupervised Learning

기계학습의 학습방법은 크게 지도학습과 비지도학습, 두가지로 나눌 수 있다. 영어로는 Supervised / Unsupervised Learning 이라고 하는데 Supervise의 사전적 의미는 ‘(v)감독하다’라는 것을 생각하면 두 학습 방법의 의미를 조금 더 쉽게 이해할 수 있을 것이다. 지도학습과 비지도학습의 가장 큰 차이는 학습 중에 나의 문제풀이와 비교할 수 있는 정답이 있는지 여부이다.
기계학습에서는 Labeled Data라고 하는데, 데이터에 라벨이 붙어있다는 의미이다. 예를 들어, 이미지 분류 작업을 한다면, A 이미지는 고양이 이미지, B 이미지는 노트북 이미지 등 주어진 모든 데이터에 대해서 해당 데이터가 어떤 그룹에 속해있는지, 혹은 기준에 포함되는지 등 문제 상황에 맞는 답이 이미 정해져 있는 데이터를 Labeled Data라고 한다. 지도학습은 Labeled Data를 사용하는 학습 기법이다. 어떤 모델을 가설로 설정한 후, 그 모델의 예측/분류 성능이 어느 정도인지 가늠할 때 모델을 적용한 예측값과 Label값을 비교하는 것이다. 가장 대표적인 지도학습 기법에는 선형회귀와 Classification(분류) 문제가 있다.

이에 반해 비지도학습은 Labeled Data를 학습에 활용하지 않는다. 미리 정답이 주어지지 않은 상황에서 모델 나름의 기준에 따라 문제를 해결하고, 대표적인 비지도학습 기법에는 Clustering이 있다.
Structured vs. Unstructured Data
마지막으로 데이터 분석에 사용하는 데이터의 종류에 대해서 알아보자. 기계학습에서 빼놓을 수 없는 것이 데이터인데, 해결해야 하는 문제에 따라서 데이터가 깔끔하게 정리되어 있는 경우가 있을 수 있고, 정리하기 애매한 형태의 데이터가 있을 수 있다. 예를 들어, 주식 가격을 예측하는 모델을 찾는다고 할 때, 사용할 수 있는 데이터는 1년 동안의 주식 가격, 투자자별 매수/매도 현황, 영업이익률 등 각 특질(feature)들을 명확하게 구분하여 나타낼 수 있다. 반면에 음성인식 모델을 만든다고 가정하면, 사람들의 대화가 녹음된 음성데이터를 사용해야 하는 건 알지만 이 음성데이터에서 어떤 특질들을 추출하여 사용해야 하는지 명확하지 않다. 전자를 Structured Data라고 하고, 후자를 Unstructured Data라고 하는데, 후자의 경우에는 특히나 데이터를 가공하고 전처리 하는데에 설계자의 경험과 능력이 모델 완성의 중요한 역할을 한다.