
오버플로우(Overflow)란?
지난 포스팅에서도 설명하였듯이 C언어에서 변수 혹은 상수의 값은 메모리에 직접 저장이 된다. 예를 들어, 아래와 같이 int 변수 a에 5라는 값을 대입하면, 컴퓨터는 알아서 ‘아 int 변수니까 메모리 4바이트만큼 할당해서 거기에 a라고 이름을 붙이고, 4바이트에 0x0005라고 저장’한다.
int a = 5;
C에서는 데이터 타입에 따라서 컴퓨터가 할당할 바이트 수가 정해져있기 때문에, 항상 오버플로우가 발생할 위험이 있고, 개발자가 신경을 잘 써야 한다. 도대체 오버플로우가 뭐길래!
메모리에서 수가 표현되는 방식 : 2진수와 2의 보수
오버플로우를 이해하기 위해서는 일단 메모리에 값이 저장되는 방식에 대해서 이해할 필요가 있다. 흔히 컴퓨터는 0과 1 밖에 모른다고 하는 것에서 알 수 있듯이, 메모리에 값이 표기되는 방식은 2진법을 따른다.
보통 int는 4바이트, long long은 8바이트를 할당받는 데이터 타입이다. 즉, int 데이터 타입을 가지는 변수는 2진수로 총 32자리(8비트 * 4바이트)까지 표현 가능하고, long long 데이터는 64자리까지 표현 가능하다는 의미이다. 각 자리별로 0 혹은 1의 값을 가지게 될테니, int는 총 2^32가지, long long은 2^64가지 수를 표현할 수 있을 것이다. 여기에서 X가지 수라고 표현하였는데, 그 이유는 signed int이냐, unsigned int이냐에 따라서 표현 가능한 수의 범위가 달라지기 때문이다.
그럼 int와 long long 데이터로 표현할 수 있는 정수의 범위를 계산해보자. 먼저 간단한 unsigned int/long long 부터 살펴보자.
unsigned는 말 그대로 음수/양수 구분이 없이 0과 양수만 표현하는 데이터 타입이다. 따라서, unsigned int는 0 ~ 2^32-1 (기억하자 2^32가지 수!), unsigned long long은 0 ~ 2^64-1까지 표현 가능하다.
문제는 음수를 어떻게 표현하느냐 하는 것인데, 컴퓨터에서 음수를 표현할 때는 2의 보수 방식을 사용한다. 2의 보수가 무엇인지 자세히 알고 싶다면 아래 유투브 강의를 참고하면 된다.
(유투브) C언어 5강 상수, 음수
간단히 설명하면, 가장 윗 비트를 부호비트로 삼고, 부호비트가 0이면 양수, 1이면 음수를 나타내는 것이다. 2의 보수를 따르면, 0xFFFF FFFF는 -1 값이고, 0x8000 0000이 int에서 표현할 수 있는 가장 큰 음수이다 (가독성을 위해 네자리씩 띄어 표기하였다).
그래서 오버플로우가 뭐라고?
이제 드디어 오버플로우가 뭔지 설명할 준비가 되었다! 말로 설명하면 이해하기 힘드니, 예를 들어 살펴보자.
int a = 0x7FFFFFFF;
int b = a + 1;
printf("a = %d, b = %d\n", a, b);
int 변수 a는 int가 표현할 수 있는 가장 큰 양수값을 가지고 있다(제일 위의 부호비트를 제외하고 모든 비트가 1로 가득차있다). 이 a의 값에 1을 더해서 b에 대입하였는데, 이 때 b의 값은 어떻게 될까? 예를 들어, a가 100만이라고(당연히 실제로는 100만이 아니다) 하면 1을 더했으니까 당연히 b은 100만 1이라는 값이라고 기대할 것이다. 그런데 웬열, b는 뜻밖에 웬 음수값이 출력된다. 어떻게 된 것일까.
여러 차례 설명했듯이 컴퓨터는 그냥 메모리에 있는 값을 읽어다가 그대로 연산하고 돌려준다. 0x7FFF FFFF + 1을 했으니까 메모리 상의 값은 0x8000 0000이 될 것이다. 문제는 메모리의 값을 가져다가 int의 방식으로 해석해야 하니까 int에서 표현할 수 있는 가장 큰 음수(예를 들어 -100만)가 출력되는 것이다. 이것이 오버플로우의 정체이다. 데이터 타입 별로 사용할 수 있는 메모리의 크기가 제한되어 있기 때문에, 표현할 수 있는 수의 범위를 넘어가는 연산을 하게 되면, 기대했던 값이 리터되지 않는 현상, 말 그대로 메모리가 차고 넘쳐 흐르는 현상이 바로 오버플로우이다.
오버플로우의 결과가 부호 변환 만은 아니다. 이번에는 unsigned int로 예를 들어보자.
unsigned int a = 0xFFFFFFFF;
unsigned int b = a + 1;
printf("a = %u, b = %u\n", a, b);
이번에는 변수 a, b 모두 unsigned int로 선언하고 a에는 가장 큰 양수 0xFFFF FFFF를 할당하였다(모든 비트가 1로 가득한). 이 값에 1을 더해 같은 unsigned int b에 대입하면 어떻게 될까? 100만 1이라는 기대한 값이 나올까? 결과는 놀랍게도 0이 나온다.
메모리에 있는 값을 가져다가 연산을 하면 이번에는 0x1 0000 0000, 16진수 8자리의 가장 큰 값에 1을 더했으니 자리수가 늘어나 9자리 수가 리턴되는 것이다. 그런데 이번에도 b는 4바이트만 사용하는 unsigned int이기 때문에 뒤의 4자리만 가져다가 표현하여 결과값이 0이 되어버린다. 이렇듯 오버플로우가 발생하면 개발자가 코드 작성 시에 예측하지 못한 오작동이 일어날 수 있기 때문에 코드 작성 시에도 항상 오버플로우의 가능성을 염두에 두어야 한다.
파이썬에서의 오버플로우
그런데 파이썬 3에서는 오버플로우가 없다는 기가 막힌 제보를 듣고, 어떻게 이게 가능한지 찾아보기로 했다. 실제 ‘python integer overflow’ 키워드로 구글링을 하니까 관련된 질문들이 많이 검색되었다.
내가 이해한 바대로 정리를 해보자면 이렇다.
- 파이썬 2에서는 정수형 데이터 타입이 int와 long 두 가지가 있었는데, int는 C에서의 그것과 같은 4바이트 데이터형이고, long은 arbitrary precision을 따르는 데이터형이다. 그래서 int 타입 변수의 값이 표현 범위를 넘어서게 되면 자동으로 long으로 타입 변경이 되는 형식이었다.
- 파이썬 3에서는 long 타입이 없어지고 int 타입만 남았는데, 이 int가 arbitrary precision을 지원하여 오버플로우가 발생하지 않게 되었다.
- 하지만 파이썬3에서도 pydata stack을 사용하는 numpy/pandas 같은 패키지를 사용할 때는 C 스타일이 유지되기 때문에 오버플로우 발생을 고려해야 한다.
arbitrary precision은 뭔데?
In computer science, arbitrary-precision arithmetic, also called bignum arithmetic, multiple precision arithmetic, or sometimes infinite-precision arithmetic, indicates that calculations are performed on numbers whose digits of precision are limited only by the available memory of the host system. (Wikipedia)
즉, arbitrary-precision은 사용할 수 있는 메모리양이 정해져 있는 기존의 fixed-precision과 달리, 현재 남아있는 만큼의 가용 메모리를 모두 수 표현에 끌어다 쓸 수 있는 형태를 이야기하는 것 같다. 예를 들어 특정 값을 나타내는데 4바이트가 부족하다면 5바이트, 더 부족하면 6바이트까지 사용할 수 있게 유동적으로 운용한다는 것이다.
Can Integer Operations Overflow in Python?
위 블로그 포스트를 참고해서 실제로 파이썬에서 아주 큰 정수를 표현할 때 사용하는 메모리의 크기가 어떻게 변화하는지 확인해봤다.
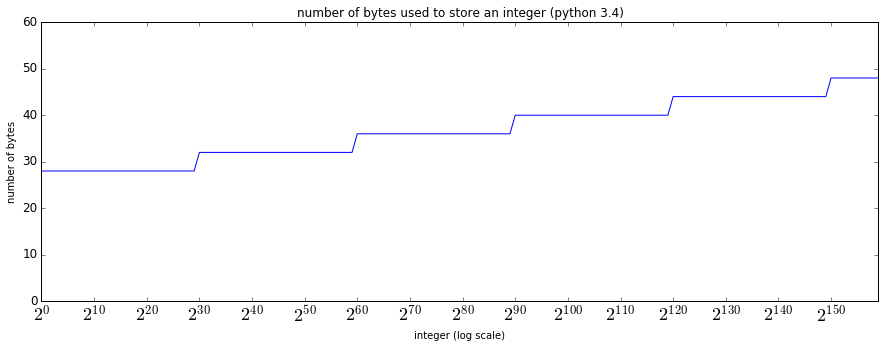
그래프를 보면 2^0부터 2^30 -1을 표현할 때까지는 28바이트(!)를 사용하다가, 2^30부터는 4바이트 늘어난 32바이트를 수 표현에 사용한다. 그 이후 일정 수를 넘어가면 4바이트씩 증가하면서 수 표현에 사용하는 바이트 수가 탄력적으로 늘어나는 것을 볼 수 있다.
여기에서 궁금한 것은 아무리 파이썬에 데이터분석에 많이 사용되는 언어라지만 그래도 보통 작은 정수를 사용하는 경우가 훨씬훨씬 많을텐데 기본적으로 사용하는 바이트수가 28바이트나 되는 건 오버헤드가 지나친 게 아닌가 하는 점이다.
어떻게 구현되어 있을까?
지난 포스트에서도 공부했듯이 파이썬에서 모든 것은 객체이다. 그렇기 때문에 X라는 수가 있다면 그것도 역시 객체로 존재하는 것이고, 객체의 attribute에 관련된 정보를 담고 있을 것이다. 파이썬에서 큰 정수가 arbitrary precision으로 구현된다면, 현재 이 수가 총 몇 바이트를 사용해서 표현되고 있는지 기억하고 있어야 할 것이고, 나는 그 정보가 정수 클래스의 ob_digit이라는 변수에 저장될 것이라고 추측했다.
// Include/longintrepr.h
// 정수 타입을 나타내는 클래스(struct)
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
그런데 여기서 궁금한 지점은 파이썬도 기본적으로 제일 밑단에서는 C API로 구현되었다고 이해하고 있는데, 4바이트 밖에 처리 못하는 C를 가지고 큰 수 표현을 어떻게 구현해냈는지이다. 마찬가지로 검색을 좀 해보니, integer array로 저장해서 초등학교 때 자리수 하나씩 계산하듯이 하면된다는 답변을 찾았다!
Quora - How is a long integer implemented in python?
그렇다면 실제로 어떻게 구현되어 있을까? (내가 코드를 이해할 수 있을까?)
CPython Include/longintrepr.h
PyObject *
PyLong_FromUnsignedLong(unsigned long ival)
{
PyLongObject *v;
unsigned long t;
int ndigits = 0;
/* Count the number of Python digits. */
t = (unsigned long)ival;
while (t) {
++ndigits;
t >>= PyLong_SHIFT;
}
v = _PyLong_New(ndigits);
if (v != NULL) {
digit *p = v->ob_digit;
Py_SIZE(v) = ndigits;
while (ival) {
*p++ = (digit)(ival & PyLong_MASK);
ival >>= PyLong_SHIFT;
}
}
return (PyObject *)v;
}