[기초 파이썬] 데이터 모델 - 파이썬에서 데이터를 표현하는 방식에는 어떤 것들이 있나
이번 포스팅은 아래 파이썬 공식 홈페이지의 설명을 나름대로 해석한 내용입니다.
The Python Language Reference - 3. Data Model
1. Objects, values and types
객체는 파이썬에서 데이터를 표현하는 방식이고, 파이썬 프로그램에서 사용되는 모든 데이터는 객체 혹은 객체 간의 특정한 관계로 나타낼 수 있다.
모든 객체는 각자의 Identity, 데이터 타입(type)과 특정 값(value)을 가지는데, 객체의 Identity는 생성된 이후 절대 바뀔 수 없다(객체가 생성된 메모리 주소라고 생각하면 된다). ‘is’ 연산은 두 객체의 ID를 비교하고, id() 함수는 해당 객체의 ID를 나타내는 정수값을 리턴한다.
객체의 타입은 해당 객체가 행할 수 있는 연산을 규정하며 (예를 들어, 이 객체는 길이라는 속성을 가지고 있나? Does it have a length?), 데이터 타입 별로 가질 수 있는 값을 정의한다. type() 함수는 객체의 데이터 타입을 리턴한다(이 역시 객체이다). 데이터 타입은 ID이기 때문에 당연히 바꿀 수 없다(unchangable).
객체의 값은 때로는 수정할 수 있는데, 값을 수정할 수 있는 객체는 mutable하다고 하며, 한번 생성되면 값을 수정할 수 없는 객체를 가리켜 immutable하다고 한다 (Immutable한 컨테이너 객체에 mutable한 객체가 들어있을 때, mutable 객체의 값을 수정하면 컨테이너 객체의 값이 바뀌겠지만, 컨테이너에 담겨있는 객체 자체는 바뀔 수 없기 때문에, 여전히 immutable하다고 여겨야 한다. 값을 수정할 수 없다는 것은 개별 값을 절대 바꿀 수 없다는 의미는 아니다). 객체의 값을 수정할 수 있는지 여부(mutability)는 객체의 데이터 타입에 따라 결정되는데, 예를 들어 숫자, 문자열 그리고 튜플은 값을 수정할 수 없고(immutable), 딕셔너리와 리스트는 값을 수정할 수 있다(mutable).
객체는 의도적으로 소멸시킬 수 없고, 다만 아무도 이를 사용하지 않을 때(when they become unreachable) garbage-collect 된다.
주의해야 할 점은 구현 중에 추적하거나 디버깅에 사용하고 있는 객체들과 try-except 구문에서 사용되는 객체들도 살아있다는 것이다. 어떤 객체는 파일이나, 윈도우 같은 외부 리소스를 참조하고 있을 수도 있다. 이런 객체들은 garbage-collect 될 때 free 된다고 여겨지지만 garbage-collect를 보장할 수 없기 때문에 명시적으로 close() 등의 함수로 리소스를 해제해야 한다. 그렇기 때문에 try-finally, with 등과 같이 명시적으로 리소스를 해제하는 구문을 사용하는 것을 추천한다.
2. The standard type hierarchy
다음은 파이썬에서 기본적으로 사용되는 데이터 타입들이다.
None
이 타입은 단 하나의 값을 가지고 있고, None 타입의 객체는 단 하나 밖에 없다 (This type has a single value. There is a single object with this value). 예약어 ‘None’으로 객체에 접근할 수 있으며, 값이 없음을 나타내야 하는 다양한 상황에 사용된다. 예를 들어, 명시적으로 어떠한 값도 리턴하지 않는 함수의 리턴값에 쓰일 수 있으며, 사실 이 값은 false와 같다.
NotImplemented
이 타입도 None과 같이 단 하나뿐이다. 예약어 ‘NotImplemented’로 접근 가능하다. 수와 관련된 연산이나 복잡한 비교를 수행하는 메소드에서 정의되어 있지 않은 연산을 수행해야 할 때 이 값을 리턴한다.
numbers.Number
수와 관련된 객체는 Immutable, 즉, 한번 생성되면 값을 바꿀 수 없다. 파이썬에서 수는 정수, 실수와 복소수를 구분한다.
- numbers.Integral
- Integers (int) : 사용 가능한 메모리가 남아있는 한 무한대의 수를 표현할 수 있다. shift, mask 연산에 대해서는 비트 단위 표현을 사용하며, 음수는 2의 보수 체계를 사용한다.
- Booleans (bool) : 참/거짓을 나타내는 타입이며, True / False 이 두 객체 밖에 없다. Integer 타입의 subtype이며, 사실 각각 1과 0으로 나타낼 수 있다. 하지만 문자열로 치환하면 ‘True’, ‘False’ (Not ‘1’, ‘0’)이 리턴된다.
- numbers.Real (float) : 아키텍처에 따라 표현 가능한 수의 범위가 달라진다. double-precision 체계를 사용한다.
- numbers.Complex (complex) : machine-level double precision 실수 체계와 짝을 이루어 복소수를 표현한다. 복소수 z는 실수부 z.real과 허수부 z.imag로 구분된다.
Sequences
Sequence는 음수가 아닌 수로 순서를 매겨 정렬된 유한한 개수의 집합이다. len() 함수를 통해 아이템 개수를 알수 있으며, 아이템이 총 n개 있을 때, 각 요소는 0, 1, … n-1로 순서를 매기며, i번째 요소는 a[i]로 접근할 수 있다.
Sequence는 슬라이싱도 지원하는데, a[i:j]와 같이 표현되며, i<= k < j 범위의 아이템을 추출할 수 있으며, 부모 Sequence와 같은 타입의 자식 Sequence가 리턴된다. 그렇기 때문에 리턴된 Sequence는 다시 0, 1 .. 부터 인덱싱된다.
일부 Sequence는 extended slicing을 지원하는데, 세번째 파라미터 step이 추가된다. a[i:j:k]와 같이 표현되며, i를 시작으로 k개씩 건너뛰며 j보다 작은 인덱스의 아이템을 추출한다.
Sequence는 Mutability(객체 생성 후 값을 수정할 수 있는지)에 따라 구분한다.
- Immutable Sequences : 객체가 한번 생성되면 값을 바꿀 수 없다 (만약 Immutable 객체가 다른 객체의 참조를 담고 있고 속한 객체가 mutable하다면 값 자체는 바뀔 수 있겠지만, Immutable 객체에 직접적으로 담겨있는 객체 참조 자체는 바뀔 수 없다).
- String : 문자열은 유니코드들의 집합이다. U+0000~U+10FFFF 사이의 유니코드를 사용할 수 있다. 파이썬에는 char 타입이 없고, 모든 유니코드 포인트들은 길이가 1인 문자열로 간주된다. ord() 함수는 각 유니코드 값을 문자열에서 정수로 변환해준다. chr() 함수는 정수값을 코드에 해당하는 길이 1의 유니코드로 변환한다. str.encode()는 str를 byte로 변환하고, bytes.decode()는 반대로 변환한다.
- Tuple :
[기초 파이썬] 파이썬 3에는 오버플로우가 없다?
오버플로우(Overflow)란?
지난 포스팅에서도 설명하였듯이 C언어에서 변수 혹은 상수의 값은 메모리에 직접 저장이 된다. 예를 들어, 아래와 같이 int 변수 a에 5라는 값을 대입하면, 컴퓨터는 알아서 ‘아 int 변수니까 메모리 4바이트만큼 할당해서 거기에 a라고 이름을 붙이고, 4바이트에 0x0005라고 저장’한다.
int a = 5;
C에서는 데이터 타입에 따라서 컴퓨터가 할당할 바이트 수가 정해져있기 때문에, 항상 오버플로우가 발생할 위험이 있고, 개발자가 신경을 잘 써야 한다. 도대체 오버플로우가 뭐길래!
메모리에서 수가 표현되는 방식 : 2진수와 2의 보수
오버플로우를 이해하기 위해서는 일단 메모리에 값이 저장되는 방식에 대해서 이해할 필요가 있다. 흔히 컴퓨터는 0과 1 밖에 모른다고 하는 것에서 알 수 있듯이, 메모리에 값이 표기되는 방식은 2진법을 따른다.
보통 int는 4바이트, long long은 8바이트를 할당받는 데이터 타입이다. 즉, int 데이터 타입을 가지는 변수는 2진수로 총 32자리(8비트 * 4바이트)까지 표현 가능하고, long long 데이터는 64자리까지 표현 가능하다는 의미이다. 각 자리별로 0 혹은 1의 값을 가지게 될테니, int는 총 2^32가지, long long은 2^64가지 수를 표현할 수 있을 것이다. 여기에서 X가지 수라고 표현하였는데, 그 이유는 signed int이냐, unsigned int이냐에 따라서 표현 가능한 수의 범위가 달라지기 때문이다.
그럼 int와 long long 데이터로 표현할 수 있는 정수의 범위를 계산해보자. 먼저 간단한 unsigned int/long long 부터 살펴보자.
unsigned는 말 그대로 음수/양수 구분이 없이 0과 양수만 표현하는 데이터 타입이다. 따라서, unsigned int는 0 ~ 2^32-1 (기억하자 2^32가지 수!), unsigned long long은 0 ~ 2^64-1까지 표현 가능하다.
문제는 음수를 어떻게 표현하느냐 하는 것인데, 컴퓨터에서 음수를 표현할 때는 2의 보수 방식을 사용한다. 2의 보수가 무엇인지 자세히 알고 싶다면 아래 유투브 강의를 참고하면 된다.
(유투브) C언어 5강 상수, 음수
간단히 설명하면, 가장 윗 비트를 부호비트로 삼고, 부호비트가 0이면 양수, 1이면 음수를 나타내는 것이다. 2의 보수를 따르면, 0xFFFF FFFF는 -1 값이고, 0x8000 0000이 int에서 표현할 수 있는 가장 큰 음수이다 (가독성을 위해 네자리씩 띄어 표기하였다).
그래서 오버플로우가 뭐라고?
이제 드디어 오버플로우가 뭔지 설명할 준비가 되었다! 말로 설명하면 이해하기 힘드니, 예를 들어 살펴보자.
int a = 0x7FFFFFFF;
int b = a + 1;
printf("a = %d, b = %d\n", a, b);
int 변수 a는 int가 표현할 수 있는 가장 큰 양수값을 가지고 있다(제일 위의 부호비트를 제외하고 모든 비트가 1로 가득차있다). 이 a의 값에 1을 더해서 b에 대입하였는데, 이 때 b의 값은 어떻게 될까? 예를 들어, a가 100만이라고(당연히 실제로는 100만이 아니다) 하면 1을 더했으니까 당연히 b은 100만 1이라는 값이라고 기대할 것이다. 그런데 웬열, b는 뜻밖에 웬 음수값이 출력된다. 어떻게 된 것일까.
여러 차례 설명했듯이 컴퓨터는 그냥 메모리에 있는 값을 읽어다가 그대로 연산하고 돌려준다. 0x7FFF FFFF + 1을 했으니까 메모리 상의 값은 0x8000 0000이 될 것이다. 문제는 메모리의 값을 가져다가 int의 방식으로 해석해야 하니까 int에서 표현할 수 있는 가장 큰 음수(예를 들어 -100만)가 출력되는 것이다. 이것이 오버플로우의 정체이다. 데이터 타입 별로 사용할 수 있는 메모리의 크기가 제한되어 있기 때문에, 표현할 수 있는 수의 범위를 넘어가는 연산을 하게 되면, 기대했던 값이 리터되지 않는 현상, 말 그대로 메모리가 차고 넘쳐 흐르는 현상이 바로 오버플로우이다.
오버플로우의 결과가 부호 변환 만은 아니다. 이번에는 unsigned int로 예를 들어보자.
unsigned int a = 0xFFFFFFFF;
unsigned int b = a + 1;
printf("a = %u, b = %u\n", a, b);
이번에는 변수 a, b 모두 unsigned int로 선언하고 a에는 가장 큰 양수 0xFFFF FFFF를 할당하였다(모든 비트가 1로 가득한). 이 값에 1을 더해 같은 unsigned int b에 대입하면 어떻게 될까? 100만 1이라는 기대한 값이 나올까? 결과는 놀랍게도 0이 나온다.
메모리에 있는 값을 가져다가 연산을 하면 이번에는 0x1 0000 0000, 16진수 8자리의 가장 큰 값에 1을 더했으니 자리수가 늘어나 9자리 수가 리턴되는 것이다. 그런데 이번에도 b는 4바이트만 사용하는 unsigned int이기 때문에 뒤의 4자리만 가져다가 표현하여 결과값이 0이 되어버린다. 이렇듯 오버플로우가 발생하면 개발자가 코드 작성 시에 예측하지 못한 오작동이 일어날 수 있기 때문에 코드 작성 시에도 항상 오버플로우의 가능성을 염두에 두어야 한다.
파이썬에서의 오버플로우
그런데 파이썬 3에서는 오버플로우가 없다는 기가 막힌 제보를 듣고, 어떻게 이게 가능한지 찾아보기로 했다. 실제 ‘python integer overflow’ 키워드로 구글링을 하니까 관련된 질문들이 많이 검색되었다.
내가 이해한 바대로 정리를 해보자면 이렇다.
- 파이썬 2에서는 정수형 데이터 타입이 int와 long 두 가지가 있었는데, int는 C에서의 그것과 같은 4바이트 데이터형이고, long은 arbitrary precision을 따르는 데이터형이다. 그래서 int 타입 변수의 값이 표현 범위를 넘어서게 되면 자동으로 long으로 타입 변경이 되는 형식이었다.
- 파이썬 3에서는 long 타입이 없어지고 int 타입만 남았는데, 이 int가 arbitrary precision을 지원하여 오버플로우가 발생하지 않게 되었다.
- 하지만 파이썬3에서도 pydata stack을 사용하는 numpy/pandas 같은 패키지를 사용할 때는 C 스타일이 유지되기 때문에 오버플로우 발생을 고려해야 한다.
arbitrary precision은 뭔데?
In computer science, arbitrary-precision arithmetic, also called bignum arithmetic, multiple precision arithmetic, or sometimes infinite-precision arithmetic, indicates that calculations are performed on numbers whose digits of precision are limited only by the available memory of the host system. (Wikipedia)
즉, arbitrary-precision은 사용할 수 있는 메모리양이 정해져 있는 기존의 fixed-precision과 달리, 현재 남아있는 만큼의 가용 메모리를 모두 수 표현에 끌어다 쓸 수 있는 형태를 이야기하는 것 같다. 예를 들어 특정 값을 나타내는데 4바이트가 부족하다면 5바이트, 더 부족하면 6바이트까지 사용할 수 있게 유동적으로 운용한다는 것이다.
Can Integer Operations Overflow in Python?
위 블로그 포스트를 참고해서 실제로 파이썬에서 아주 큰 정수를 표현할 때 사용하는 메모리의 크기가 어떻게 변화하는지 확인해봤다.
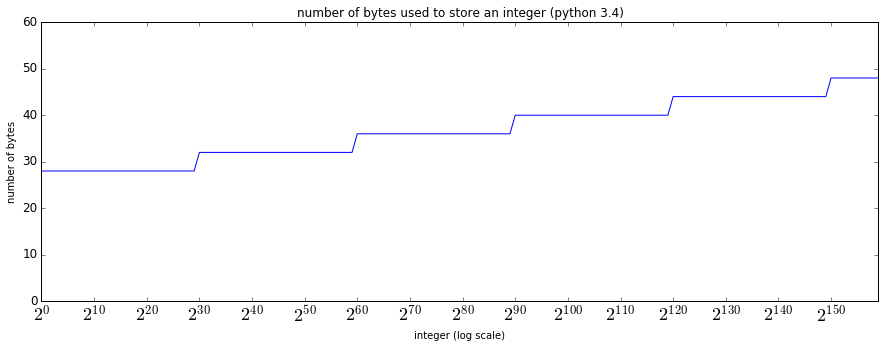
그래프를 보면 2^0부터 2^30 -1을 표현할 때까지는 28바이트(!)를 사용하다가, 2^30부터는 4바이트 늘어난 32바이트를 수 표현에 사용한다. 그 이후 일정 수를 넘어가면 4바이트씩 증가하면서 수 표현에 사용하는 바이트 수가 탄력적으로 늘어나는 것을 볼 수 있다.
여기에서 궁금한 것은 아무리 파이썬에 데이터분석에 많이 사용되는 언어라지만 그래도 보통 작은 정수를 사용하는 경우가 훨씬훨씬 많을텐데 기본적으로 사용하는 바이트수가 28바이트나 되는 건 오버헤드가 지나친 게 아닌가 하는 점이다.
어떻게 구현되어 있을까?
지난 포스트에서도 공부했듯이 파이썬에서 모든 것은 객체이다. 그렇기 때문에 X라는 수가 있다면 그것도 역시 객체로 존재하는 것이고, 객체의 attribute에 관련된 정보를 담고 있을 것이다. 파이썬에서 큰 정수가 arbitrary precision으로 구현된다면, 현재 이 수가 총 몇 바이트를 사용해서 표현되고 있는지 기억하고 있어야 할 것이고, 나는 그 정보가 정수 클래스의 ob_digit이라는 변수에 저장될 것이라고 추측했다.
// Include/longintrepr.h
// 정수 타입을 나타내는 클래스(struct)
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
그런데 여기서 궁금한 지점은 파이썬도 기본적으로 제일 밑단에서는 C API로 구현되었다고 이해하고 있는데, 4바이트 밖에 처리 못하는 C를 가지고 큰 수 표현을 어떻게 구현해냈는지이다. 마찬가지로 검색을 좀 해보니, integer array로 저장해서 초등학교 때 자리수 하나씩 계산하듯이 하면된다는 답변을 찾았다!
Quora - How is a long integer implemented in python?
그렇다면 실제로 어떻게 구현되어 있을까? (내가 코드를 이해할 수 있을까?)
CPython Include/longintrepr.h
PyObject *
PyLong_FromUnsignedLong(unsigned long ival)
{
PyLongObject *v;
unsigned long t;
int ndigits = 0;
/* Count the number of Python digits. */
t = (unsigned long)ival;
while (t) {
++ndigits;
t >>= PyLong_SHIFT;
}
v = _PyLong_New(ndigits);
if (v != NULL) {
digit *p = v->ob_digit;
Py_SIZE(v) = ndigits;
while (ival) {
*p++ = (digit)(ival & PyLong_MASK);
ival >>= PyLong_SHIFT;
}
}
return (PyObject *)v;
}
[기초 파이썬] 파이썬의 모든 것은 Object이다 (정수편)
C에서 변수가 저장되는 방식 : 변수 = 메모리
C에서 특정한 값이 변수에 저장되는 방식은 간단하다. 예를 들어, 아래와 같은 C코드가 작성되어 있다고 하자.
// C 코드
int a = 5;
int b = a;
코드를 실행하는 세부 과정은 다음과 같다.
- int 4바이트 만큼의 메모리를 할당하고 a라는 이름을 붙인다 (컴퓨터는 a를 방금 할당한 메모리의 주소로 기억한다.)
- 변수 a 자리에 5를 저장한다. (0x5의 형태로 4바이트만큼 사용할 것이다.)
- int 4바이트 만큼의 메모리를 다시 할당하고 b라는 이름을 붙인다.
- 변수 a에 있는 값을 꺼내서(당연히 5일 것이다) 변수 b에 저장한다.
이렇듯 C코드에서의 변수는 메모리를 직접적으로 나타내고, 변수의 값은 할당한 메모리에 저장되어 있는 실제 값을 나타낸다. 그런데 파이썬에서는 변수를 다른 방식으로 관리한다고 한다!
파이썬에서 변수가 저장되는 방식 : Everything is Object
파이썬에서는 모든 것(부울, 정수, 실수, 문자열, 데이터 구조, 함수, 프로그램)이 객체(Object)로 구현되어 있다. … 파이썬 변수의 핵심을 살펴보자. 변수는 단지 이름일 뿐이다. 할당한다는 의미는 값을 복사하는 것이 아니다. 데이터가 담긴 객체에 그냥 이름을 붙이는 것이다. 그 이름은 객체 자신에 포함되는 것이라기보다는 객체의 참조다. 이름을 포스트잇처럼 생각하자. (Introducing Python p.42-43)
간단히 말해 5라고 하는 값이 사실은 객체였다는 것이다. 정수는 정수 클래스의 객체로, 문자열은 문자열 클래스의 객체로, 모든 변수와 값들이 사실은 객체로 다루어지고 있다는 것이다. C에서는 변수 a에 5라는 값을 저장하고, 변수 b에 변수 a의 값을 대입하면, 5라는 값이 “복사”되었다. 그런데 파이썬에서는 변수가 자신만을 위한 메모리를 가지는 것이 아니라 5라는 값을 가진 객체를 가리키도록 되어있다는 것이다.
# 파이썬 코드
a = 5
b = a
같은 로직의 위 코드를 실행하면 5라는 값을 가지는 정수 객체가 생기고, 변수 a와 변수 b는 단지 정수 5 객체의 주소를 참조하게 되는 것이다. 이 과정에 대해서 더 자세히 설명하고 있는 블로그의 설명을 들여다봐보자.
Why python is Slow:Looking Under the Hood
위 블로그 글에서는 파이썬 코드가 일반적으로 왜 느린지에 대해서 설명하면서 자연스럽게 파이썬에서 변수가 어떤 식으로 관리되고 있는지에 대해서 힌트를 준다.
정수(실수, 문자열 등) 클래스는 어떻게 생겼을까?
파이썬의 변수는 특정 값을 가지는 객체의 참조라고 이야기했다. 그렇다면 그 객체는 어떤 정보들을 담고 있어야 할까?
- value : 5라는 정수 값, 혹은 5.0 실수값, ‘string’이라는 문자열 값 등 이 객체가 나타내는 값을 지니고 있어야 한다.
- data type : 알다시피 파이썬에서는 변수를 선언하고 초기화할 때 변수의 데이터 타입을 명시하지 않는다. 그렇기 때문에 연산을 할 때마다 해당 변수가 어떤 타입의 데이터인지 확인해야 값은 ‘+’ 연산을 하더라도 덧셈을 할 것인지, 문자열 이어붙이기를 할 것인지 수행하는 작업이 달라질 수 있다.
- reference count : 몇 개의 변수가 나를 사용하고 있는지 알아야 한다. 아무도 나를 사용하지 않는다면 굳이 메모리를 차지하면서 있을 필요가 없을테니까.
생각나는 속성들은 이 정도인데 실제 파이썬 코드에도 이렇게 구현이 되어 있을까 궁금하다. 위 블로그 글의 Digging into Python Integers 부분을 보면 실제 파이썬 C API 쪽에 구현되어 있는 클래스들을 분해하여 설명하고 있다.
// Include/longintrepr.h
// 정수 타입을 나타내는 클래스(struct)
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
// Include/object.h
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
// 위 struct와 typedef를 합치고 당장 이해하기 어려운 정보들을 빼면 실제로 아래와 같다.
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
위에서 추측했던대로 reference count(ob_refcnt), object type(ob_type), value(ob_digit), 그리고 하나 데이터의 사이즈(ob_size)의 속성을 담고 있다.
그리고 같은 값(255보다 작은)을 나타내는 변수가 생성되면 새로운 값을 가진 객체를 또 만들어내는 것이 아니라, singleton으로 이미 있는 객체를 리턴하고 reference count를 하나 증가시킨다.
x = 42
y = 42
id(x) == id(y)
id()는 객체의 주소값을 리턴하는 함수이다. 위의 코드를 실행하면 변수 x, y 모두 42 값을 가지기 때문에 42 객체의 주소 값이 리턴되고 True가 출력될 것이다.